
핀포인트 웹에 안 들어가지거나 연결이 안 됨
ps -ef | grep java # 시스템에서 실행 중인 모든 프로세스 중에서 "java"라는 문자열을 포함하는 프로세스들의 정보를 보여주는 데 사용나의 이슈는 hbase가 안 떠져있어서 연결이 안 됐었다. 핀포인트 웹은 들어가지는데 애플리케이션이 안 된다면 로그가 뜰 테니 그걸로 디버깅해 보거나 아예 들어가지 지도 않는다면 agent > logs, collector > logs, web > logs를 다 확인해봐야 한다.
그렇지만 대부분의 경우
- 필요한 것들이 다 잘 실행 중이고,

hbase, collector, web (+ was와 agent) 실행 중 - Agent 부분에서 config를 잘 설정했고,

ip 수정 - 인바운드 설정도 잘했다면

문제가 없을 가능성이 크다. (3가지를 잘 확인해 보자.)
`REAL TIME > Active Request` ERROR로 뜸
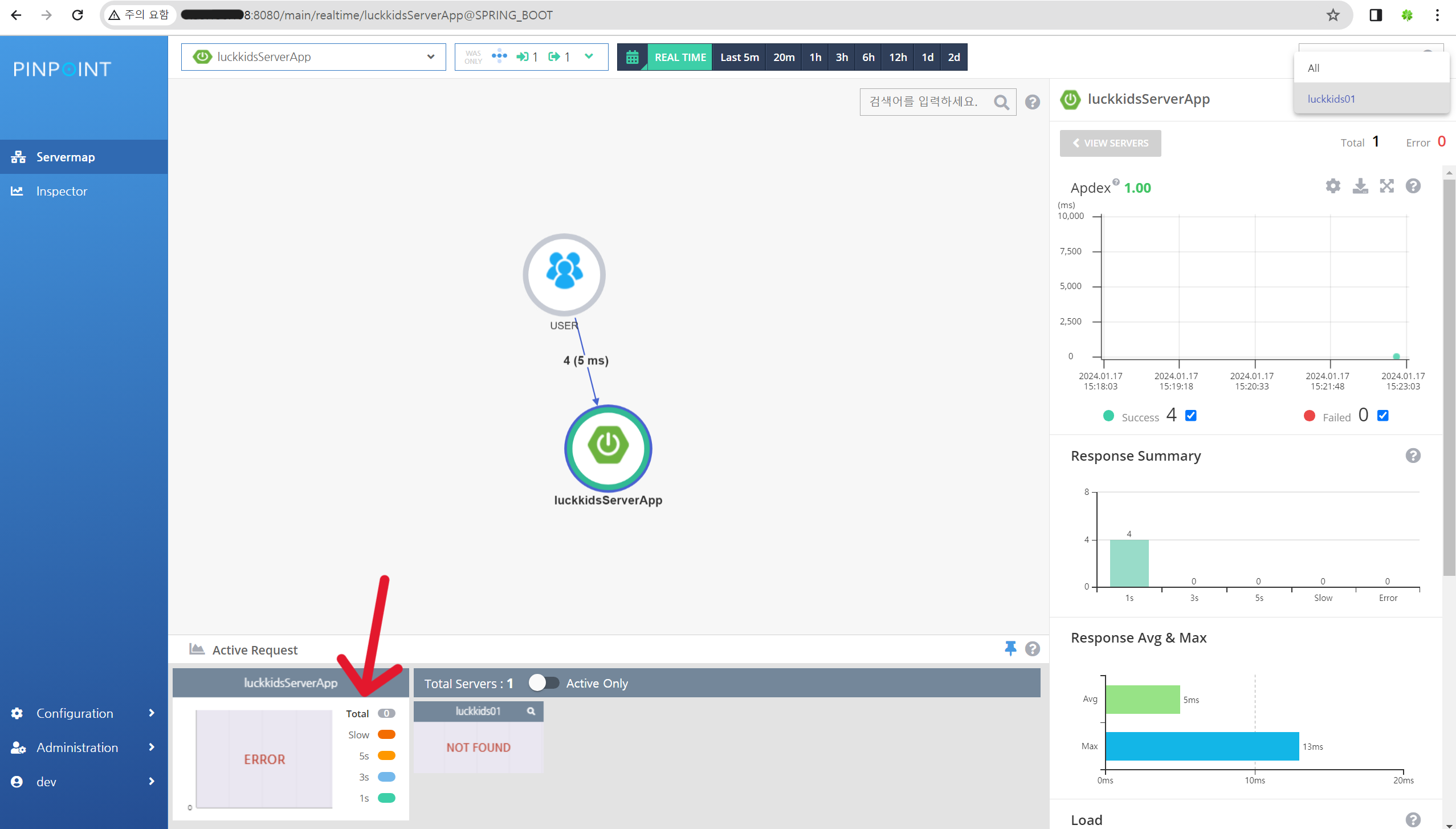
- 화면을 보면 REAL TIME으로 했을 때 실시간으로 모든 동작은 다 잘 되는데 Active Request만 ERROR라고 뜬다.
- https://lemontia.tistory.com/809 비슷한 이슈의 글이 있어서 가져와 봤는데 나의 경우에서는 가장 처음에는 차트도 잘 작동해서 조금 다른 것 같다. 아직 문제를 찾지 못했다..ㅠㅠ (이용하는데 큰 문제는 없음)
EC2 메모리 부족?
우선 메모리가 2기가는 많이 부족하다. 그렇다고 스케일업을 하기에는 부담이 있어서 가상 메모리 기법을 사용해보려고 한다.
- EC2에서 메모리가 부족할 땐 가상 메모리 기법을?이라는 글을 보면 스왑 공간을 사용할 수 있게 설정할 수 있다.
- 하나 다른 점은 t4g.small은 메모리가 2기가이기 때문에 ` sudo fallocate -l 4G /swapfile` 4기가로 설정해 줬다.

스왑 파일을 사용하여 Amazon EC2 인스턴스의 스왑 공간으로 메모리 할당
Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에서 스왑 파일로 사용할 메모리를 할당하려고 합니다. 어떻게 해야 하나요?
repost.aws
스왑공간까지 늘려줬는데 자꾸 hbase만 어느 순간 보면 다운되어 있다. 정확히 이게 메모리 부족으로 다운된 건지 다른 이유가 있는 건지 확인하기 위해 log를 확인해 봤는데 정확히 이유를 파악하기 힘들어서 AWS CloudWatch로 메모리 사용량을 모니터링해 볼 예정이다.
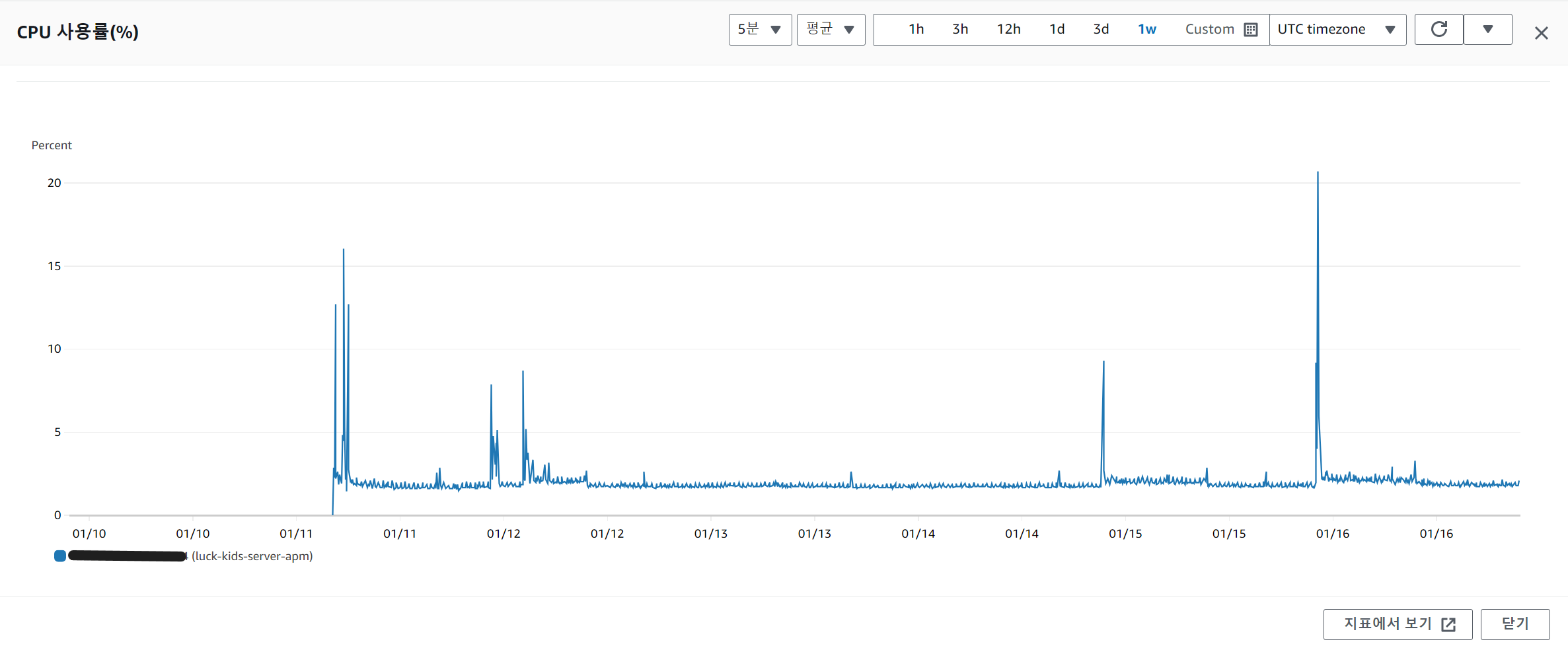
HBASE 다운..?
앞서 숨긴 글에 말한 것처럼 어느 순간 보면 핀포인트가 작동을 안 해서 확인해 보면 자꾸 hbase가 다운되어 있다.

이렇게 3개가 실행 중이어야 정상인데 핀포인트가 작동이 안 될 때는 항상 hbase가 실행 중인 프로세스에 없다.. 이유는 메모리 사용량 때문이라고 추측 중인데 더 확인해봐야 할 문제일 것 같다.
트러블 슈팅
hbase 로그 분석
첫 번째 문제
# /hbase-1.2.7/logs log 파일
2024-01-18 00:02:24,684 INFO [main] zookeeper.ZooKeeper: Initiating client connection, connectString=localhost:2181 sessionTimeout=120000 watcher=clean znode for master0x0, quorum=localhost:2181, baseZNode=/hbase
2024-01-18 00:02:24,701 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2024-01-18 00:02:24,709 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:716)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
2024-01-18 00:02:25,825 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2024-01-18 00:02:25,825 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:716)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
2024-01-18 00:02:25,926 ERROR [main] zookeeper.RecoverableZooKeeper: ZooKeeper getData failed after 1 attempts
2024-01-18 00:02:25,926 WARN [main] zookeeper.ZKUtil: clean znode for master0x0, quorum=localhost:2181, baseZNode=/hbase Unable to get data of znode /hbase/master
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:99)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:51)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:1155)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:354)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataNoWatch(ZKUtil.java:713)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.deleteIfEquals(MasterAddressTracker.java:267)
at org.apache.hadoop.hbase.ZNodeClearer.clear(ZNodeClearer.java:149)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:141)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2532)
2024-01-18 00:02:25,926 ERROR [main] zookeeper.ZooKeeperWatcher: clean znode for master0x0, quorum=localhost:2181, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:99)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:51)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:1155)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:354)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataNoWatch(ZKUtil.java:713)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.deleteIfEquals(MasterAddressTracker.java:267)
at org.apache.hadoop.hbase.ZNodeClearer.clear(ZNodeClearer.java:149)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:141)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2532)
2024-01-18 00:02:25,927 WARN [main] zookeeper.ZooKeeperNodeTracker: Can't get or delete the master znode
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:99)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:51)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:1155)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:354)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataNoWatch(ZKUtil.java:713)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.deleteIfEquals(MasterAddressTracker.java:267)
at org.apache.hadoop.hbase.ZNodeClearer.clear(ZNodeClearer.java:149)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:141)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2532)
2024-01-18 00:02:26,926 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2024-01-18 00:02:27,027 INFO [main] zookeeper.ZooKeeper: Session: 0x0 closed
2024-01-18 00:02:27,027 INFO [main-EventThread] zookeeper.ClientCnxn: EventThread shut down
첫 번째 문제 해결
# conf/hbase-site.xml
<configuration>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>604800000</value> <!-- 밀리초 단위, 여기서는 7일로 설정 -->
</property>
<property>
<name>hbase.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name >hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
</configuration>`Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect` 이 에러를 보면 SASL 사용해서 인증 시도하는데 실패한다고 되어있다. 그래서 8.2. Apache HBase에 대한 간단한 사용자 액세스라는 문서를 참고하여 hbase-site.xml을 수정해 줬다.
두 번째 문제
org.apache.zookeeper.keeperexception$sessionexpiredexception: keepererrorcode = session expired for /hbase/master비슷한 글로 hbase Session expire로 shutdown 되는 현상이라는 글이 있어서 적용을 해봤는데 아직도 중간에 끊기게 된다.
01/19 계속 시도
우선 zookeeper.session.timeout을 3분으로 늘리고 hbase를 다시 stop ➜ start 하니까 잘 되긴 하는데 언제 또 다운될지는 모르겠다..
https://github.com/pinpoint-apm/pinpoint/issues/10625
Session expired (hbase Session expire로 shutdown 되는 현상) 해결이 안 돼서 도움 부탁드립니다 .. ㅠ · Issue
Prerequisites Please check the FAQ, and search existing issues for similar questions before creating a new issue.YOU MAY DELETE THIS PREREQUISITES SECTION. I have checked the FAQ, and issues and fo...
github.com
쉽게 해결할 수 있는 문제일 수도 있겠지만 처음인 저에겐 너무 어려워서 힌트라도 던져주시거나 경험을 공유해 주신다면 정말 도움이 될 것 같습니다 ㅠㅠ 🙇
01/19 또다시 6분 만에 다운
2024-01-19 10:19:23,797 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2024-01-19 10:19:23,819 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused로그를 확인해 보면 아직 SASL인증을 사용하는 것 같아서 `bin/start-hbase.sh` 파일을 수정해 줬다.
# ...
. "$bin"/hbase-config.sh
# Set HBASE_OPTS here to include java options like disabling SASL for Zookeeper
export HBASE_OPTS="$HBASE_OPTS -Dzookeeper.sasl.client=false"
# start hbase daemons
# ...
if [ "$distMode" == 'false' ]
then
"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master $@
else
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" $commandToRun zookeeper
"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \
--hosts "${HBASE_REGIONSERVERS}" $commandToRun regionserver
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \
--hosts "${HBASE_BACKUP_MASTERS}" $commandToRun master-backup
fi
# ...
01/19 또또 다시 다운
hbase가 다운되기 직전 로그를 정리해 보면,
Client session timed out
# ZooKeeper 클라이언트 세션 타임아웃: 로그에 여러 차례 Client session timed out이라는 메시지가 나타나고 있음.
# 이는 HBase가 ZooKeeper 서버와의 연결을 유지하지 못하고 있음을 나타냄.
# 이러한 연결 문제는 네트워크 지연, ZooKeeper 서버의 과부하, 또는 ZooKeeper 서버의 오류로 인해 발생할 수 있음.
SplitLogManager Timeout Monitor missed its start time 및 HFileCleaner missed its start time
# SplitLogManager 및 HFileCleaner 작업 지연: SplitLogManager Timeout Monitor missed its start time 및 HFileCleaner missed its start time과 같은 메시지는 HBase의 내부 스케줄 작업이 예정된 시간에 시작하지 못했음을 나타냄.
# 이는 시스템의 성능 문제나 자원 부족으로 인해 발생할 수 있음.
took 20948 ms appending an edit to wal
# WAL(Write-Ahead Logging) 지연: took 20948 ms appending an edit to wal 메시지는 WAL 작업이 예상보다 훨씬 더 오래 걸리고 있음을 나타냄.
# 이는 디스크 I/O 병목, 높은 시스템 부하, 또는 네트워크 문제로 인해 발생할 수 있음.CloudWatch로 메모리 사용량부터 모니터링해 보는 게 우선일 것 같다.
(확인해 본 결과, 스왑공간까지는 메모리가 다 할당되지는 않았었다..)
언제나 잘못된 설명이나 부족한 부분에 대한 피드백은 환영입니다🤍